
xml is a bad format because it’s tedious for people to write and being text-based it’s inefficent for computers too. worst of both worlds
that extends to html. with how much of a pain writing html by hand is - it is possible to make a website in notepad, but it’s a soulcrushing chore! - i can see where the popularity of web frameworks comes from
so the web platform is overall kind of a disaster and it might be a wheel worth reinventing
 2
2
 1
1
 1
1
Celes 🌙
celestia@tech.lgbt@hsza I've been praising xml recently so I feel slightly called out 
but yes, I agree with you, it's a very inefficient format and it's clumsy to write, it's just sad that there's no good alternative that works for the particular case of intertwining text and semantic metadata at multiple levels of nesting 
and I wonder how a "better xml" would look like, because I can't really think of any alternatives...
JSON / YAML / TOML are for a different use case, even if they call themselves "markup" languages they're more like data transmission languages and they wouldn't be a good way to represent a web page
and things like markdown / latex / typst are very opinionated DSLs for a very specific kind of document and wouldn't even begin to cover what HTML covers these days
1
0
1
telephone of margaret thatcher [TudbuT]
tudbut@social.tudbut.de@hsza i disagree on the html. check out what my html looks like:
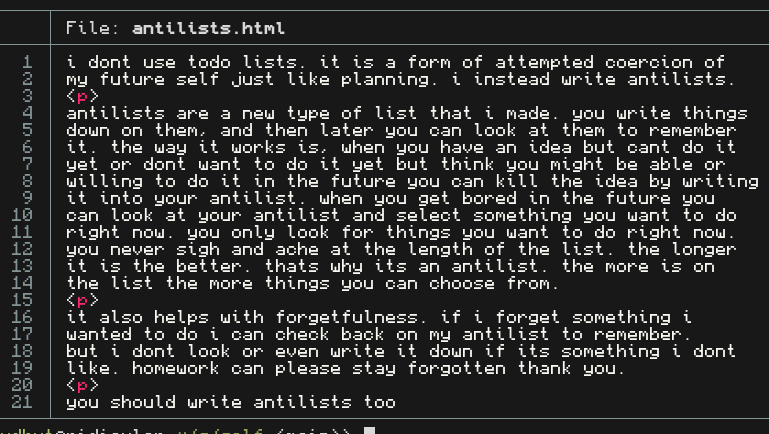
 2
0
0
2
0
0
telephone of margaret thatcher [TudbuT]
tudbut@social.tudbut.de@hsza yep. if the browser can read it its valid enough for me. who gaf if it isnt to spec
1
0
0
telephone of margaret thatcher [TudbuT]
tudbut@social.tudbut.de@hsza and even internet explorer can read this soo
0
0
0
@tudbut re: “antilists”
ive just always been calling exactly that a todo list  i suppose it being the things you actually want to do (but not nessesarily have the energy for in the moment) as opposed to chores can make it a little distinct
i suppose it being the things you actually want to do (but not nessesarily have the energy for in the moment) as opposed to chores can make it a little distinct
1
0
1
telephone of margaret thatcher [TudbuT]
tudbut@social.tudbut.dei suppose it being the things you actually want to do (but not nessesarily have the energy for in the moment)
thats not what they are. they are idea lists only, completely neutral as to whether you want to do it or not, and unrelated to energy
0
0
0
kasdeya
kasdeya@celestia @hsza to be honest I’d love if even just the syntax (and not the semantics) of HTML was changed out to something a little more readable. like consider the difference between this:
<body>
<div class="foo" some-attr="bar">
text goes here
<div class="empty-tag-example"></div>
</div>
</body>
and these:
body:
div.foo(some-attr="bar"):
text goes here
div.empty-tag-example:
(body (div.foo {some-attr "bar"}
"text goes here"
(div.empty-tag-example)))
IMO the bottom two are a lot easier to read because there’s less syntactic noise
1
0
3
 2
0
1
2
0
1
Celes 🌙
celestia@tech.lgbt 0
0
2
0
0
2
@celestia @kasdeya what about something like
;title hello
[body
[div.foo:some-attr=bar
text goes here
;div.empty-tag-example
example [a:href=https://example.com:some-attr=foo link] that is inline
]
;div.bar this div is just for this line
]
 it looks like the single-line construct extends the content until the end of the line so you'd have to
1
0
1
it looks like the single-line construct extends the content until the end of the line so you'd have to
1
0
1
Celes 🌙
celestia@tech.lgbt@hsza @kasdeya oh right, yeah silly me  then I don't think I want the single-line version for much since I'd be using the multiline one for everything, it looks succint enough
then I don't think I want the single-line version for much since I'd be using the multiline one for everything, it looks succint enough
another thing that might need fixing is attributes, some attributes (for example the style attribute) have their own syntax inside and something like a quote-less :attr=value does not cover it, but probably something like :attr="value" would be fine?
1
0
2
1
0
1
@celestia @kasdeya another question is whether we want to disambiguate what exactly gets closed with a ] like html does (probably nessesary for parity)
say in html you have
<b>bold<i>bitalic</b>italic</i>
situations like that
of course you could just do
[b bold][b[i bitalic]][i italic]
to reproduce that but id imagine in more comprex cases that might end up cubersome
2
0
1
@celestia @kasdeya a fairly obvious leap of logic: placing the element name after the ] disambiguates
[b bold [i bitalic]b italic]
but then there’s a different issue:
[i iii[b bold]iiii]
if we disambiguate closures this way, the “i” after [b bold] gets eaten and the last 3 are bold and not italic, and that might not be what we want! so we have to have a way to explicitly mark closures as undisambiguated, say, by placing a dot right after the closure
[i iii[b bold].iiii]

@celestia @kasdeya html is very silly like that. actually wait what the actual hell is the point of xml having you write out what exactly you’re closing every time if such silliness is not allowed?!?
my brain is starting to hurt a little too from all this
anyway letting ]s eat dots seems like a solid idea, but if the user cares not for the disambiguation they’ll still have to keep that mechanism in mind and place a double dot if they want a geniune dot after an element closure, which can be a little annoying, but that probably is the cost of supporting partially overlapping elements like that
1
0
1
1
0
1
1
0
1
1
0
1
Celes 🌙
celestia@tech.lgbtit's handwritten as opposed to generated, it means you don't use a parser generator to specify some sort of declarative grammar and then have a tool turn that into code, but write the code yourself
recursive descent means (roughly) that your code is shaped like the structure you want to parse, so if your grammar has statements, and expressions and blocks you'll have functions like parseBlock(), parseStatement() and parseExpression() in it, and they will call each other, sometimes recursively (an expression contains sub-expressions, so it calls parseExpression)
(cont'd due to char limit)
1
0
2
Celes 🌙
celestia@tech.lgbt@hsza @kasdeya pratt precedence refers to an operator-precedence parser. most parts of your language can be parsed using traditional recursive descent, but there are some, which typically correspond to expressions in prorgamming languages that are a bit trickier, like 1 + 2 * 4 - 3 is parsed as (sub (add 1 (mul 2 4)) 3), but doing that is tricky unless you have the right tools. pratt parsing is that tool, the wikipedia article might be helpful for some context https://en.wikipedia.org/wiki/Operator-precedence_parser, but imo this blog post is a better introduction https://matklad.github.io/2020/04/13/simple-but-powerful-pratt-parsing.html, oh and nerding aobut pratt parsing is probably the only good thing douglas crockford has ever done in his life so this one's a nice read too https://www.crockford.com/javascript/tdop/tdop.html
0
0
2